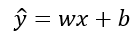搜索到
1
篇与
的结果
-
 机器学习概览 机器学习根据数据集和工作内容的不同可以分为监督学习、无监督学习和强化学习。监督学习是目前用到较多的一种,它一般指数据集中有标签,即我们的学习目标是一个确定的,不管是回归还是分类任务;无监督学习是只有数据集,让机器自动学习特征,比如电商平台的推荐算法,聚类算法及现在超火的AIGC;强化学习指通过与环境的交互来学习如何做出决策,在实际环境中给予模型惩罚和奖励,使其不断完善,从而获得更大的收获,比如围棋人机对战。对于机器学习,完整的流程为:输入数据→预测→计算损失→计算梯度→更新参数……从简单的线性回归讲起,一个简单的线性回归模型可以写为:w为权重,b为偏置。 {x} 损失函数损失函数即模型预测值与真实值之间的偏差,以均方根误差来说就是:模型训练的目标就是要让损失函数达到最小,那如何调整参数使损失函数减小呢?这就涉及到了梯度下降。 {x} 梯度下降 那么什么是梯度呢?什么是梯度下降呢?梯度可参考高等数学中偏导数内容。梯度的方向就是函数值增长最快的方向,反之梯度的反方向就是函数值下降最快的方向。根据偏导数公式,可以得到损失函数的梯度为:基于梯度公式,参数更新的公式可以表示为:这里的η也就是我们常说的学习率,一般的学习率需要根据经验设定。学习率过小,模型收敛过慢,时间长;学习率大,模型振荡,甚至可能无法收敛。梯度下降常见的一些算法:动量法、AdaGrad、自适应矩估计(Adam),Adam是深度学习中使用最广泛的首选优化器。 {x} 线性回归模型的评估欠拟合和过拟合解决欠拟合:特征工程,增加训练轮数,增加模型复杂度抑制过拟合的常见方法包括:正则化(Ridge的L2,Lasso的L1),减小训练轮数,增加训练数据,降低模型复杂度,Dropout等方法常见的机器学习算法包括线性回归算法、逻辑回归算法、k-means聚类算法、决策树(随机森林)、PCA降维下一章节深度学习:深度学习(DL)又叫神经网络,属于机器学习(ML)的一种,机器学习属于人工智能(AI)领域内容深度学习之所以叫深度学习实在是因为没办法,至暗时刻学界提及深度学习则被至之一旁,那就是由于大名鼎鼎的异或问题,单层感知机面对异或问题时进入死胡同,数学上可证明无解。虽然多层感知机可以很好的解决这个问题,但是受限于多层网络参数优化的问题,在当时并不具备竞争力。直至链式法则带来的反向传播算法才让深度学习迎来了新的曙光。
机器学习概览 机器学习根据数据集和工作内容的不同可以分为监督学习、无监督学习和强化学习。监督学习是目前用到较多的一种,它一般指数据集中有标签,即我们的学习目标是一个确定的,不管是回归还是分类任务;无监督学习是只有数据集,让机器自动学习特征,比如电商平台的推荐算法,聚类算法及现在超火的AIGC;强化学习指通过与环境的交互来学习如何做出决策,在实际环境中给予模型惩罚和奖励,使其不断完善,从而获得更大的收获,比如围棋人机对战。对于机器学习,完整的流程为:输入数据→预测→计算损失→计算梯度→更新参数……从简单的线性回归讲起,一个简单的线性回归模型可以写为:w为权重,b为偏置。 {x} 损失函数损失函数即模型预测值与真实值之间的偏差,以均方根误差来说就是:模型训练的目标就是要让损失函数达到最小,那如何调整参数使损失函数减小呢?这就涉及到了梯度下降。 {x} 梯度下降 那么什么是梯度呢?什么是梯度下降呢?梯度可参考高等数学中偏导数内容。梯度的方向就是函数值增长最快的方向,反之梯度的反方向就是函数值下降最快的方向。根据偏导数公式,可以得到损失函数的梯度为:基于梯度公式,参数更新的公式可以表示为:这里的η也就是我们常说的学习率,一般的学习率需要根据经验设定。学习率过小,模型收敛过慢,时间长;学习率大,模型振荡,甚至可能无法收敛。梯度下降常见的一些算法:动量法、AdaGrad、自适应矩估计(Adam),Adam是深度学习中使用最广泛的首选优化器。 {x} 线性回归模型的评估欠拟合和过拟合解决欠拟合:特征工程,增加训练轮数,增加模型复杂度抑制过拟合的常见方法包括:正则化(Ridge的L2,Lasso的L1),减小训练轮数,增加训练数据,降低模型复杂度,Dropout等方法常见的机器学习算法包括线性回归算法、逻辑回归算法、k-means聚类算法、决策树(随机森林)、PCA降维下一章节深度学习:深度学习(DL)又叫神经网络,属于机器学习(ML)的一种,机器学习属于人工智能(AI)领域内容深度学习之所以叫深度学习实在是因为没办法,至暗时刻学界提及深度学习则被至之一旁,那就是由于大名鼎鼎的异或问题,单层感知机面对异或问题时进入死胡同,数学上可证明无解。虽然多层感知机可以很好的解决这个问题,但是受限于多层网络参数优化的问题,在当时并不具备竞争力。直至链式法则带来的反向传播算法才让深度学习迎来了新的曙光。